[자료구조 기본] 배열
배열이란, 연속적인 메모리 공간에 동일한 타입의 데이터를 저장하는 기본적인 형태의 자료구조 입니다.
여기에서 중요한 것은 물리적으로 연속적인 메모리 공간이고 동일한 타입을 저장한다는 것입니다.
C++ (C++ 11)에서는 std::array라는 표준 템플릿 라이브러리(Standard Template Library, STL)가 추가되었습니다.
특징
1. 빠른 접근 (Random Access)
배열에서는 각 동일한 타입의 요소가 물리적으로 연속적인 메모리 공간에 저장되어 있기 때문에, Index를 통해 어떤 요소에도 빠르게 접근할 수 있습니다.
그 이유는 동일한 타입. 즉, 동일한 크기로 메모리 공간을 나누었기에 가능합니다.
C++에서는 특정 주소를 통해 메모리의 특정 공간에 직접 접근 가능합니다.(ex. 포인터) 그리고 메모리 공간을 할당할 때, 바이트(byte) 단위로 나누어 할당하고 있습니다.
따라서, 만약 데이터의 타입이 4바이트이고, 배열의 시작 주소가 0x0010이라면, 여섯 번째 요소의 시작 주소는 0x0010 + 20(10) = 0x0024로 계산해서 바로 접근이 가능합니다. (0x로 시작하는 주소는 16진수입니다. cf. 0x0010 = 16(10), 0x0024 = 36(10))
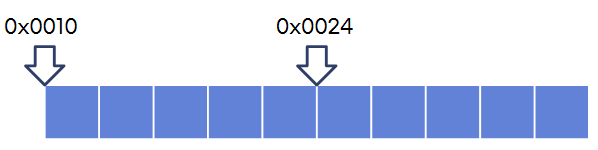 동일한 크기로 나누어진 메모리 공간은, 시작 주소를 알면 특정 위치에 대해 빠르게 계산하고 접근할 수 있습니다.
동일한 크기로 나누어진 메모리 공간은, 시작 주소를 알면 특정 위치에 대해 빠르게 계산하고 접근할 수 있습니다.
예를 들어, 배열의 시작 주소가 arr이고, 데이터 타입이 int형이라면, 아래와 같이 이해하면 될 것 같습니다.
\[\mathtt{arr[index]=arr+(int×index)}\]사실, C 문법으로 배열을 만드는 경우에 배열의 이름은 배열의 첫 번째 요소를 가리키는 포인터로 간주됩니다.
따라서, 배열의 특정 인덱스에 있는 요소에 접근하려면, 배열의 이름(포인터)에 인덱스를 더하면 됩니다. (포인터의 덧셈 또는 뺄셈 연산은 해당 포인터가 가리키는 데이터 타입의 크기만큼 주소를 이동 시킵니다.)
\[\mathtt{arr[index]=*(arr+index)}\]1
2
int arr[10];
(arr + 5); // arr[5]
2. 고정된 크기
물리적인 메모리 공간에 연속적으로 저장하는 특성상 배열은 생성시에 정해진 크기를 가집니다.
어쩌면, “당연한거 아닌가?”하고 생각할 수 있지만, 상대적으로 다른 자료구조에 비해 단점에 해당하는 부분입니다.
우선, 설명을 드리자면, 배열을 동적으로 할당한다고 하더라도 배열 메모리의 바로 다음 주소에 어떤 데이터가 들어있을지 예측하기 어렵기 때문에 배열을 할당하고 나서 메모리 크기를 확장하는 것은 위험합니다.
즉, 다른 데이터의 손상에 대한 위험성이 있기 때문에, 배열의 크기를 동적으로 변경하기 어렵습니다.
따라서, 배열의 크기는 고정되어 있기 때문에, 배열을 생성할 때 필요한 최대 크기를 미리 예측해야 하며, 배열이 가득 차면 새로운 요소를 추가하기 위해서는 전체 배열을 더 큰 크기의 새로운 배열로 복사해야 합니다.
만약, 배열의 크기가 자주 변경되어야 한다면, 빠른 접근(Random Access)의 필요 여부에 따라 다른 자료구조가 더 적합할 수 있습니다.
다차원 배열
다차원 배열은 데이터를 다층적으로 저장하는 방법입니다.
흔히, 배열을 배우고 나서 2차원 배열이란 것을 배우고, 그 다음으로 3차원 배열이라는 것을 배우게 되는데, 이때 사용하는 표현이 2차원 3차원 형태의 큐브 구조입니다.

하지만, 이 배열이라는 것은 형태를 arr[1][2][3][4][5]와 같이 무수히 확장시킬 수 있습니다.
따라서 저는 위의 그림보다는 아래의 그림을 조금 더 선호하는 편이고, 이 편이 나중에 배열형 자료구조의 다차원 구조를 그리는데 도움이 될 것이라고 생각합니다.
아래 그림은 다차원 배열을 확장이라는 개념으로 이미지화 시킨 것입니다.
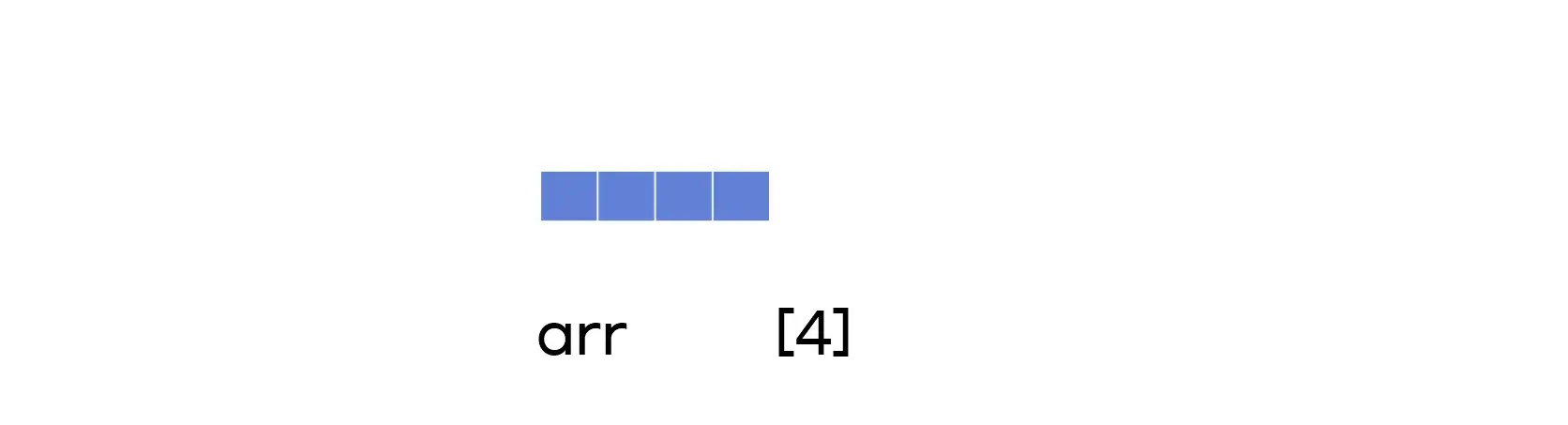 이미지를 중앙부터 표현하느라 확장 순서가 헷갈릴 수 있지만, 메모리는 나란히 확장된다고 생각하시면 좋을 것 같습니다.
이미지를 중앙부터 표현하느라 확장 순서가 헷갈릴 수 있지만, 메모리는 나란히 확장된다고 생각하시면 좋을 것 같습니다.
위 그림은, [4]개짜리 같은 배열을 [3]개의 배열로 확장하고, 그 [3]개짜리 같은 배열을 [2]개의 배열로 확장하는 것을 표현한 것입니다.
즉, int arr[2][3][4]는 int [4] 크기의 자료를 [3]개짜리 배열로 만들 크기를 계산하고,
이 int [3][4] 크기의 자료를 다시 [2]개짜리 배열로 만들 크기를 계산하고,
배열을 만들어 arr이라는 변수에 대입한다고 생각하면 좋을 것 같습니다.
쉽게 생각하면, 우측에서부터 좌측 방향으로 읽어 배열을 확장시킨다고 생각할 수 있습니다.
($\normalsize {arr[4]}$짜리 배열을 $\normalsize {arr[3][\small{arr[4]}]}$로 만들고, 이 배열을 $\large{arr[2][\normalsize {arr[3][\small{arr[4]}]}]}$ 로 만든다!)

예제
너무 어려웠을까요?
3차원 배열의 예제를 통해서 알아보겠습니다.
아래 코드는 3차원 배열을 만들고 각 배열 그룹의 크기를 출력합니다.
즉, $\mathtt{int\ arr[?]}$짜리 배열의 각 요소의 크기가 $\mathtt{int}$의 크기라는 것을 증명하고,
$\mathtt{int\ arr[?][4]}$짜리 배열의 각 요소의 크기가 $\mathtt{int×4}$의 크기라는 것을,
$\mathtt{int\ arr[?][3][4]}$짜리 배열의 각 요소의 크기가 $\mathtt{int×3×4}$의 크기라는 것을 증명하는 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#include <iostream>
#include <array>
using namespace std;
int main()
{
int arr[2][3][4] =
{
{ { 0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} },
{ { 12, 13, 14, 15}, {16, 17, 18, 19}, {20, 21, 22, 23} }
};
cout << arr[0][1][2] << endl; // 6
cout << "------------------------------" << endl;
// 각 첫번째 배열의 요소와 주소값을 출력
for (int i = 0; i < 2; i++)
{
cout << "arr[" << i << "] = " << arr[i][0][0] << " (" << arr[i] << ")" << endl;
if (i + 1 < 2)
{
// 두 주소 값의 차이를 byte 단위로 출력
cout << "arr[1] - arr[0] : " << (long long)&arr[1] - (long long)&arr[0] << " byte" << endl;
}
}
cout << "------------------------------" << endl;
// 각 두번째 배열의 요소와 주소값을 출력
for (int j = 0; j < 3; j++)
{
cout << "arr[0][" << j << "] = " << arr[0][j][0] << " (" << arr[0][j] << ")" << endl;
if (j + 1 < 3)
{
// 두 주소 값의 차이를 byte 단위로 출력
cout << "arr[0][" << j + 1 << "] - arr[0][" << j << "] : " << (long long)&arr[0][j + 1] - (long long)&arr[0][j] << " byte" << endl;
}
}
cout << "------------------------------" << endl;
// 각 세번째 배열의 요소와 주소값을 출력
for (int k = 0; k < 4; k++)
{
cout << "arr[0][0][" << k << "] = " << arr[0][0][k] << " (" << &arr[0][0][k] << ")" << endl;
if (k + 1 < 4)
{
// 두 주소 값의 차이를 byte 단위로 출력
cout << "arr[0][0][" << k + 1 << "] - arr[0][0][" << k << "] : " << (long long)&arr[0][0][k + 1] - (long long)&arr[0][0][k] << " byte" << endl;
}
}
}
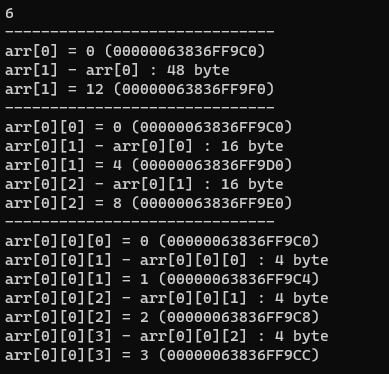
각 $\mathtt{int\ arr[?][3][4]}$ 배열의 요소는 $\mathtt{int\ arr[3][4]}$이므로 $4byte×3×4$로 $48byte$가 나옵니다.
정리
최대한 이해하기 쉽게 써본다고 써봤는데, 이해가 되셨을지 모르겠습니다.
다차원 배열쪽은 천천히 이해한다고 해도 나머지 부분은 자료구조로써 중요한 개념이기에 다시 정리 해보겠습니다.
- 연속적인 메모리 공간에 동일한 타입의 데이터를 저장하는 기본적인 형태의 자료구조
- Index를 통해 어떤 요소에도 빠르게 접근할 수 있다. (Random Access)
- 배열의 크기는 컴파일 혹은 할당 시점에 고정되어 있다.
- 할당시 최대 크기를 예상해서 할당한다.
- 최대 크기를 넘어갈 때, 더 큰 크기의 배열을 새로 만들고 기존의 요소를 복사해야 한다.