Call By Value, Call By Address, Call By Reference 란?
Call by Value, Call by Address, Call by Reference는 함수 호출 메커니즘에서 매개변수를 전달하는 세 가지 주요 방식으로, 실제 매개변수와 형식 매개변수가 어떻게 상호작용 하는지, 어떻게 쓰이는지에 따라 구분한 방식입니다.
‘Call by’는 함수 호출을 의미하며 Value, Address, Reference는 각각 값, 주소, 참조 전달을 의미합니다.
- 실제 매개변수란 함수 호출시 실제 인자로 넣어주는 변수
- 형식 매개변수는 함수 선언시 매개변수로 정의한 변수
Call by Value
함수가 호출될 때 실제 매개변수의 값이 형식 매개변수에 복사됩니다.
따라서, 값을 복사하기 때문에 실제 매개변수와 형식 매개변수는 각각 다른 메모리 주소를 가지게 되고, 하나를 변경해도 다른 하나에는 영향을 미치지 않습니다.
장점
- 원본 데이터가 변경되지 않으므로, 데이터 무결성(data integrity)을 유지하는 데 유용합니다.
- 크기가 작은 기본 데이터 타입(int, float 등)을 사용할 때 복사의 비용이 크지 않으므로 Address나 Reference보다 유용할 수 있습니다.
단점
- 크기가 큰 데이터의 경우 메모리 사용량이 증가할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
using namespace std;
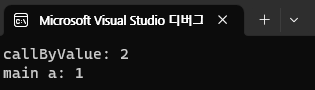
void callByValue(int a)
{
a = 2;
cout << "callByValue: " << a << endl;
}
int main()
{
int a = 1;
callByValue(a);
cout << "main a: " << a << endl;
}
Call by Address
실제 매개변수의 주소 값을 형식 매개변수에 전달하여 저장하는 방식입니다.
형식 매개변수가 실제 매개변수의 주소를 저장하므로 두 매개변수는 간접적으로 같은 변수를 공유합니다. 따라서, 형식 매개변수에서의 값 변경이 실제 매개변수에도 반영됩니다.
장점
- 크기가 큰 데이터를 사용할 때, 메모리를 효율적으로 사용할 수 있습니다.
- 데이터의 복사 비용 없이 원본 데이터를 쉽게 변경할 수 있습니다.
단점
- 포인터를 사용하므로 코드가 복잡해질 수 있습니다.
- 장점이자 단점으로 하나 더 추가하자면, 원본 데이터가 쉽게 변경될 수 있으므로 데이터 무결성(data integrity)을 유지할 수 없을 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
using namespace std;
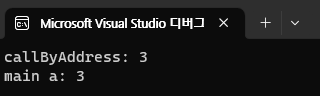
void callByAddress(int* a)
{
*a = 3;
cout << "callByAddress: " << *a << endl;
}
int main()
{
int a = 1;
callByAddress(&a);
cout << "main a: " << a << endl;
}
Call by Reference
실제 매개변수를 형식 매개변수에 직접적으로 전달해 실제 매개변수와 형식 매개변수가 같은 메모리 주소를 직접적으로 공유합니다.
따라서, 형식 매개변수를 실제 데이터를 다루듯이 다룰 수 있습니다.
다만, 참조를 잘 못 사용해 임시 변수가 생성되는 경우에는 의도한대로 동작하지 않을 수 있습니다.
Call by Reference 의 장단점은 Call by Address와 비슷합니다.
장점
- 크기가 큰 데이터를 사용할 때, 메모리를 효율적으로 사용할 수 있습니다.
- 원본 데이터를 다루듯이, 데이터의 복사 비용 없이 원본 데이터를 쉽게 변경할 수 있습니다.
단점
- 원본 데이터가 쉽게 변경될 수 있으므로 데이터 무결성(data integrity)을 유지할 수 없을 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
using namespace std;
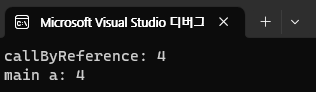
void callByReference(int& a)
{
a = 4;
cout << "callByReference: " << a << endl;
}
int main()
{
int a = 1;
callByReference(a);
cout << "main a: " << a << endl;
}
Call by Address와 Call by Reference의 차이
포인터와 참조의 차이
만약, 이 두 방식의 차이점을 좀 더 찾고 싶어서 주소를 출력해 봤다면 다음과 같은 결과를 얻을 수 있을 것 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
using namespace std;
void callByAddress(int* a)
{
cout << "callByAddress:\t\t" << &a << "\n";
cout << "callByAddress-value:\t" << a << "\n\n";
}
void callByReference(int& a)
{
cout << "callByReference:\t" << &a << "\n\n";
}
int main()
{
int a = 1;
cout << "main a Address:\t\t" << &a << "\n\n";
callByAddress(&a);
callByReference(a);
}
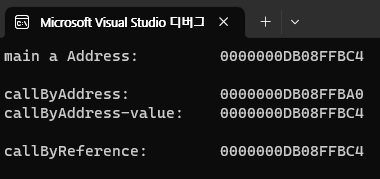
메인 주소와 참조 주소, 포인터가 가지고 있는 주소는 같지만, 포인터 자체의 주소는 다릅니다.
포인터는 주소를 담는 변수이고 참조는 원본 데이터의 실제 이름 대신 사용할 수 있는 별칭(alias)으로 원본 데이터 그 자체를 가리킨다고 볼 수 있기 때문입니다.
위에서 이 둘을 설명할 때에도 Call by Address는 실제 매개변수의 주소 값을 형식 매개변수가 저장하기 때문에, 형식 매개변수의 주소 값은 원본과 다르고 형식 매개변수가 원본의 주소 값을 저장한다고 볼 수 있습니다.
Call by Reference는 실제 매개변수와 형식 매개변수가 같은 메모리 주소를 직접적으로 공유한다고 했기 때문에, 원본과 형식 매개변수의 주소 값은 같아 보입니다.
이것이 포인터와 참조의 차이라고 볼 수 있고, 주소로 부른다는 Call by Address의 의미를 좀 더 명확히 알 수 있습니다.
로우 레벨(어셈블리)에서의 차이
이전 포스트에서 보면 참조와 포인터는 로우 레벨에서 볼 때 두 동작의 차이가 거의 없다고 설명했습니다.
그러나 디스어셈블리의 결과를 보면 조금 달라 보이기도 합니다.
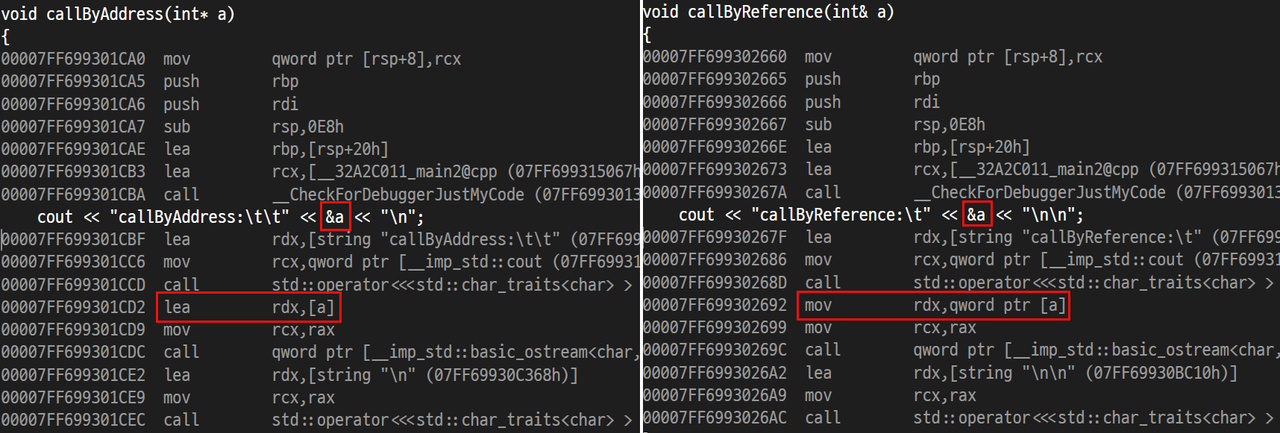
callByAddress의 lea rdx,[a] 명령어는 “Load Effective Address”의 약자로, 이 명령어는 실제 데이터를 로드하는 것이 아니라 주소 자체를 로드합니다. 즉, [a]의 주소를 rdx 레지스터에 저장합니다.
callByReference의 mov rdx,qword ptr [a] 명령어는 [a]에서 8바이트(64비트, qword) 데이터를 읽어 rdx 레지스터에 저장합니다. 즉, [a] 메모리 주소에 저장된 실제 값을 로드합니다.
따라서, lea는 주소 계산만 수행하여 주소만 가져오는 것이며, mov는 실제 데이터를 메모리에서 읽어 레지스터에 저장하므로 Call by Address와 Call by Reference의 구분이 명확 한 것처럼 보일 수 있습니다.
하지만 실제 두 동작은 차이가 거의 없다.
하지만, 실제 값을 사용하는 부분을 보면 두 동작의 차이가 없음을 알 수 있습니다.
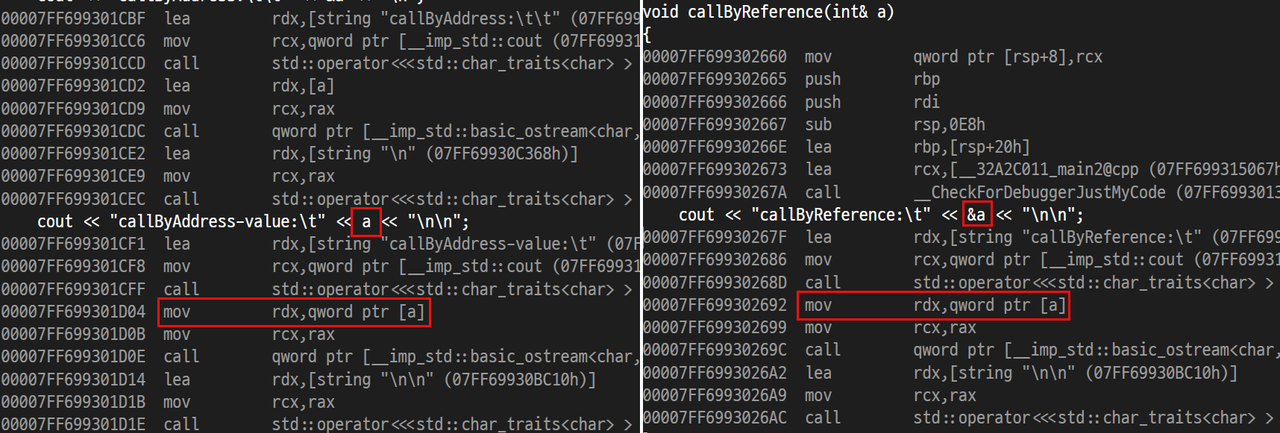
callByAddress에서 원본 주소를 가리키는 것과 callByReference에서 원본 주소를 가리키는 코드는 C++에서는 달라 보이지만, 로우 레벨(어셈블리)에서는 같은 것을 확인할 수 있습니다.
실제 데이터를 조작하는 부분을 보더라도 로우 레벨(어셈블리) 코드는 같은 것을 확인할 수 있습니다.

결론
사실, 참조(Reference)라는 개념이 C에서 없었고 C++에서 등장한 만큼 어셈블리 언어 자체에 큰 변화가 생기지 않았습니다.
즉, C++ 컴파일러가 어셈블리 코드를 생성할 때, 특별한 어셈블리 문법을 사용한게 아니라 기존의 포인터의 동작과 유사하게 만든다고 볼 수 있습니다.
따라서 참조(Reference)는 고수준 언어에서의 프로그래밍 편의성과 안전성을 높이기 위한 개념으로 보실 수 있습니다.
그러므로 Call by Address, Call by Reference의 차이는 다음과 같이 정리할 수 있을 것 같습니다.
- Call by Address는 포인터를 사용하고 Call by Reference는 참조를 사용합니다.
- Call by Address는
NULL상태로 받을 수 있지만, Call by Reference는 유효한 객체를 받아야 합니다. - Call by Address는 함수 내에서 형식 매개변수의 주소를 변경할 수 있지만, Call by Reference는 주소를 변경할 수 없습니다.
- Call by Address는
NULL을 받을 수 있기 때문에 함수 선언시 디폴트 인자로NULL또는nullptr을 사용할 수 있습니다. (참조의 경우에는 오버로딩을 사용할 수 있습니다.)
이런 차이점들이 있다고 볼 수 있을 것 같습니다.
물론, 컴파일러의 최적화에 따라 로우 레벨(어셈블리)에서 포인터 연산에 약간의 오버헤드가 발생하는 경우가 있을 수 있습니다.
하지만, 그 성능의 차이가 크지 않을 것으로 보이고, 그보다 참조를 사용하는 이유는 안전성 때문이라고 생각합니다.