[STL] array
개요
- 헤더 파일:
<array> - STL 시퀀스 컨테이너 (sequence container): 선형 자료구조
- 탐색 시간: $O(1)$ (임의 접근)
std::array는 배열의 STL 버전입니다.
자료 구조의 형태는 고정된 크기의 배열 그 자체지만, 기존의 배열을 사용하는데 있어서 문제점은 인덱스를 직접 지정해 줄 수 있기 때문에, 잘못된 위치로 접근할 위험성이 존재했었습니다.
또한, 배열을 함수의 매개변수로 전달해 줄 때, 배열의 크기를 따로 넘겨줘야 하는 귀찮음이 있었습니다.
하지만, STL 버전의 std::array는 배열을 객체로 만들어서 STL의 이터레이터를 사용해 안전하게 쓸 수 있게 하면서도 필요한 정보를 담고 있는 배열을 만들 수 있습니다.
특징
- 고정된 크기의 배열입니다.
- 이터레이터를 사용하여 안전하게 탐색할 수 있습니다.
- 배열을 표현한 객체로, 다양한 정보를 담고 있습니다.
장단점
장점
- 안정성과 편의성: STL의 다른 컨테이너와 마찬가지로 이터레이터를 제공합니다. 이는 STL 알고리즘과의 호환성을 의미하며, 정렬, 검색 등의 연산을 쉽게 수행할 수 있습니다.
- 객체 지향적 특성:
std::array는 클래스로 구현되어 있어, 메서드와 멤버 함수를 제공합니다. 따라서 배열의 크기를 내장하고 있고,size()함수를 통해 언제든지 배열의 크기를 알 수 있습니다. - 임의 접근:
std::array는 배열의 임의 접근 특징을 그대로 가져옵니다. 다만, 이렇게 접근하는 경우에는 안정성이 떨어질 수 있습니다. (인덱스를 벗어날 수 있습니다.)
단점
- 크기의 유연성 부족: 이는 기존 C++과 같은 단점으로, 실행 중에 크기를 변경할 수 없습니다. 다음에 나오는
std::vector라는 동적 배열과 비교했을 때 단점으로 작용할 수 있습니다. - 약간의 오버헤드:
std::array는 일반 배열보다 추가적인 기능을 제공하기 때문에, 매우 성능에 민감한 상황에서는 기본 배열이 더 나을 수 있습니다. 그러나 이러한 오버헤드는 미미하기 때문에 안전성을 위해 가 더 나을 수 있습니다.- 다른 STL 자료구조에 비하면 오버헤드의 단점은 없다고 보면 될 것 같습니다.
사용법
생성자
1
std::array<typename _Ty, size_t _Size>
생성자의 형태는 위와 같으므로 이렇게 선언하여 생성합니다.
std::array는 집합체 초기화(Aggregate Initialization)를 지원하기 때문에, 기존 배열처럼 사용할 수 있습니다.
1
array<int, 5> arr = {1, 2, 3, 4, 5};
다차원 배열
array 또한 배열이기 때문에, 기존에 쓰던 다차원 배열을 생성할 수 있습니다.
다만, 그 방법은 조금 다릅니다.
기존의 배열 $\large{arr[2][\normalsize {arr[3][\small{arr[4]}]}]}$는 요소 ‘4’개짜리 1차원 배열을 ‘3’개짜리 2차원 배열로 만들고, 이 요소로 ‘2’개짜리 3차원 배열을 만듭니다.
이걸 이해하고 계신다면 아래와 같이 생성할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <iostream>
#include <array>
int main()
{
std::array<std::array<std::array<int, 4>, 3>, 2> arr2;
// 배열의 각 요소에 값을 할당하는 부분
int value = 0;
for (auto dim1_it = arr2.begin(); dim1_it != arr2.end(); dim1_it++)
{
for (auto dim2_it = dim1_it->begin(); dim2_it != dim1_it->end(); dim2_it++)
{
for (auto dim3_it = dim2_it->begin(); dim3_it != dim2_it->end(); dim3_it++)
{
*dim3_it = value++;
}
}
}
// 배열의 각 요소를 출력하는 부분
for (auto dim1_it = arr2.begin(); dim1_it != arr2.end(); dim1_it++)
{
for (auto dim2_it = dim1_it->begin(); dim2_it != dim1_it->end(); dim2_it++)
{
for (auto dim3_it = dim2_it->begin(); dim3_it != dim2_it->end(); dim3_it++)
{
std::cout << *dim3_it << " ";
}
std::cout << std::endl;
}
std::cout << std::endl;
}
}
사실, 범위기반 for문이나 size()를 통해 사용하는 편이 더 간편합니다. (이터레이터를 사용하는 예시를 만들기 위해 다소 복잡한 방법을 사용했습니다.)
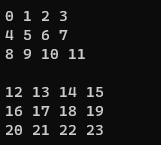
STL의 각 템플릿 매개변수 괄호(각괄호)는 그 안에 자료형이 들어가므로, 4개짜리 int형 array를 만들고, 이 자료형을 사용해 3개짜리 array를 만들어가는 식으로 만들 수 있습니다.
멤버 함수
| 함수 | 설명 |
|---|---|
| arr.begin() | 배열의 첫 번째 원소를 가리키는 이터레이터를 반환합니다. |
| arr.end() | 배열의 마지막 원소 다음을 가리키는 이터레이터를 반환합니다. (마지막 원소가 아닌 종료 지점을 가리킵니다.) |
| arr.rbegin() | 배열을 역순으로 순회할 때 첫 번째 원소를 가리키는 역방향 이터레이터를 반환합니다. |
| arr.rend() | 배열을 역순으로 순회할 때 마지막 원소 다음을 가리키는 역방향 이터레이터를 반환합니다. |
| arr.front() | 배열의 첫 번째 원소에 대한 참조를 반환합니다. |
| arr.back() | 배열의 마지막 원소에 대한 참조를 반환합니다. |
| arr.data() | 배열의 첫 번째 원소의 주소를 반환합니다. (배열을 포인터 타입으로 반환) |
| arr.at(N) | N번째 원소에 대한 참조를 반환합니다. (만약 인덱스 범위를 벗어난다면 예외를 throw 합니다.) |
| arr[N] | N번째 원소에 대한 참조를 반환합니다. (C++의 일반 배열과 같은 방법으로 접근하기 때문에, 약간 더 빠를 수 있지만, 위험할 수 있습니다.) (다른 조건 검사와 같은 동작을 하지 않기 때문에) |
| arr.empty() | 배열이 비어있는지 여부를 반환합니다. (비어있으면 true) |
| arr.size() | 배열의 크기를 반환합니다. (max_size()와 동일) |
| arr.max_size() | 배열의 최대 크기를 반환합니다. (size()와 동일) |
| arr.fill(val) | 배열의 모든 원소를 val 값으로 채웁니다. |
| arr.swap(arr2) | arr2와 배열의 원소들을 교환합니다. (길이와 타입이 같아야 합니다.) |